Twitter Recommendation Algorithm
Desentrañando el funcionamiento detrás de tu timeline
by Manolo Garcia on 2023-03-31T23:29:00.000Z
Introducción
En este blog, exploraremos el algoritmo de recomendación de Twitter, que es el núcleo de cómo Twitter crea y muestra la timeline de inicio a sus usuarios.
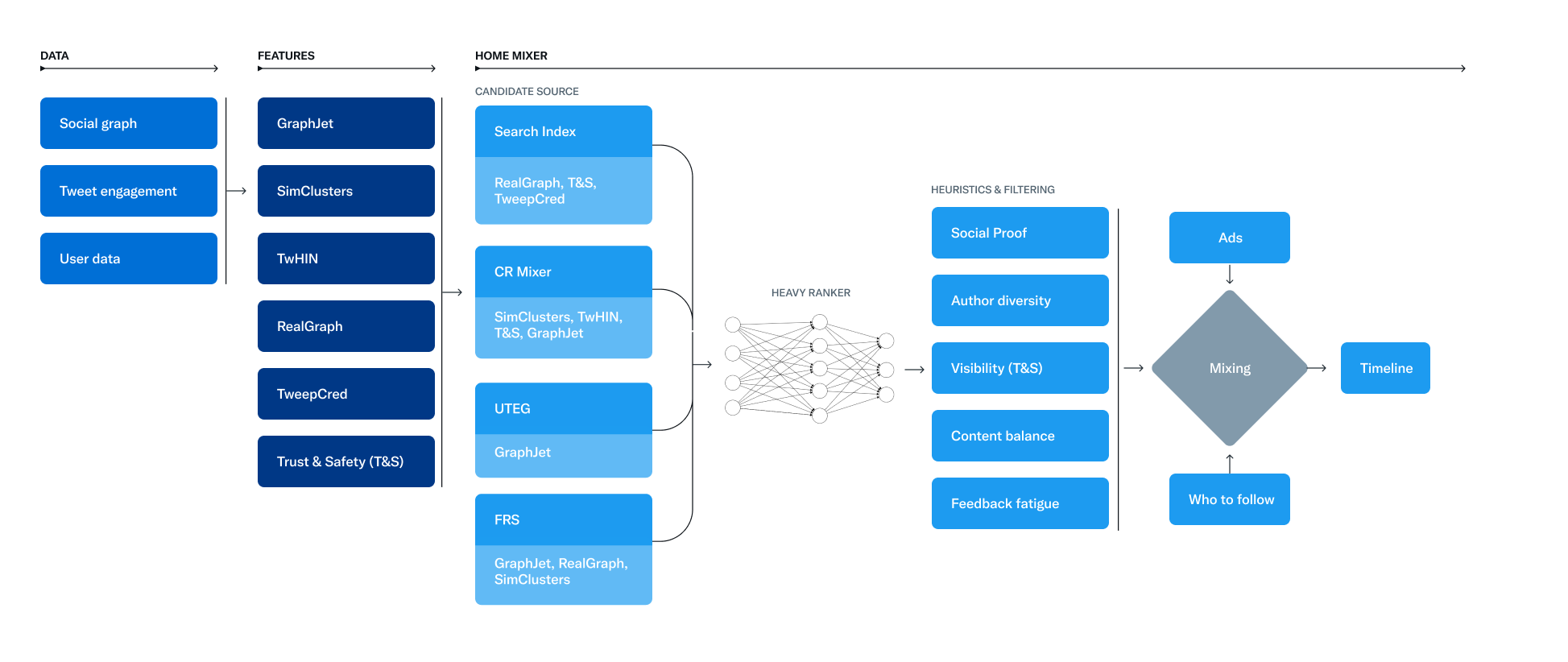
Este conjunto de servicios y trabajos es responsable de construir y servir el contenido que ves en tu timeline.
Para obtener una visión general de cómo funciona el algoritmo, consulta nuestra entrada en el blog de ingeniería.
A continuación, analizaremos cómo los principales componentes y trabajos se interconectan para brindarte una experiencia única en Twitter.
Componentes principales del algoritmo de recomendación de Twitter
El algoritmo de recomendación de Twitter consta de varios componentes esenciales, cada uno de los cuales cumple un propósito específico. A continuación, se detallan los componentes principales incluidos en este repositorio:
- SimClusters: Detecta comunidades y crea embeddings dispersos dentro de esas comunidades.
- TwHIN: Genera embeddings densos de grafos de conocimiento para usuarios y tweets.
- trust-and-safety-models: Detecta contenido no seguro para el trabajo (NSFW) o abusivo.
- real-graph: Predice la probabilidad de que un usuario de Twitter interactúe con otro usuario.
- tweepcred: Utiliza el algoritmo Page-Rank para calcular la reputación del usuario de Twitter.
- recos-injector: Procesador de eventos en tiempo real para construir flujos de entrada para servicios basados en GraphJet.
- graph-feature-service: Proporciona características de grafos para un par dirigido de usuarios (por ejemplo, cuántos seguidores del usuario A dieron "me gusta" a los tweets del usuario B).
- search-index: Encuentra y clasifica tweets dentro de la red. Aproximadamente el 50% de los tweets provienen de esta fuente de candidatos.
- cr-mixer: Capa de coordinación para obtener candidatos a tweets fuera de la red de servicios de cálculo subyacentes.
- user-tweet-entity-graph (UTEG): Mantiene un gráfico de interacción usuario-tweet en memoria y encuentra candidatos basados en recorridos de este gráfico. Se basa en el marco GraphJet.
- follow-recommendation-service (FRS): Recomienda a los usuarios cuentas para seguir y tweets de esas cuentas.
- light-ranker: Modelo ligero utilizado por el índice de búsqueda (Earlybird) para clasificar tweets.
- heavy-ranker: Red neuronal para clasificar candidatos a tweets. Uno de los principales indicadores utilizados para seleccionar tweets en la timeline después de la obtención de candidatos.
- home-mixer: Servicio principal utilizado para construir y servir la timeline de inicio. Construido sobre product-mixer.
- visibility-filters: Filtra el contenido de Twitter para cumplir con la legalidad, mejorar la calidad del producto, aumentar la confianza del usuario y proteger los ingresos mediante el uso de filtrado riguroso, tratamientos de productos visibles y degradado de granularidad gruesa.
- timelineranker: Servicio heredado que proporciona tweets con puntuación de relevancia desde el índice de búsqueda Earlybird y el servicio UTEG.
- navi: Un marco de servicio de modelos de aprendizaje automático de alto rendimiento, escrito en Rust.
- product-mixer: Un marco de software para construir feeds de contenido.
- twml: Un marco heredado de aprendizaje automático construido sobre TensorFlow v1.
Cada uno de estos componentes juega un papel crucial en la construcción y personalización de la timeline de inicio de cada usuario en Twitter.
Cómo funcionan juntos estos componentes
Los componentes del algoritmo de recomendación de Twitter trabajan juntos para garantizar que se muestre contenido relevante y atractivo en tu timeline de inicio. Estos son algunos ejemplos de cómo interactúan los componentes:
- Los servicios SimClusters y TwHIN colaboran para crear embeddings que ayudan a agrupar usuarios y tweets similares.
- Los modelos trust-and-safety y real-graph trabajan juntos para prevenir contenido abusivo y mejorar la calidad de las interacciones entre usuarios.
- El servicio follow-recommendation (FRS) utiliza información de user-tweet-entity-graph (UTEG) y graph-feature-service para sugerir cuentas para seguir y tweets de esas cuentas.
- Los servicios light-ranker y heavy-ranker se encargan de clasificar y seleccionar los tweets más relevantes para incluir en la timeline de inicio.
- El componente home-mixer utiliza la información de todos los componentes anteriores para construir y servir la timeline de inicio personalizada para cada usuario.
Conclusión
El algoritmo de recomendación de Twitter es un conjunto complejo de componentes y servicios que trabajan juntos para brindar a los usuarios una experiencia personalizada en su timeline de inicio.
Desde la detección de comunidades y la creación de grafos de conocimiento hasta la clasificación y filtrado de tweets, cada componente desempeña un papel esencial en la creación de una timeline atractiva y relevante para cada usuario.
A medida que Twitter continúa mejorando y optimizando su algoritmo, podemos esperar una experiencia de usuario aún más personalizada y atractiva en el futuro.